Using certificate transparency to search for malicious domains.

Today, we'll be looking at public certificate transparency logs, to determine if we can identify malicious websites at the point of certificate issuance.
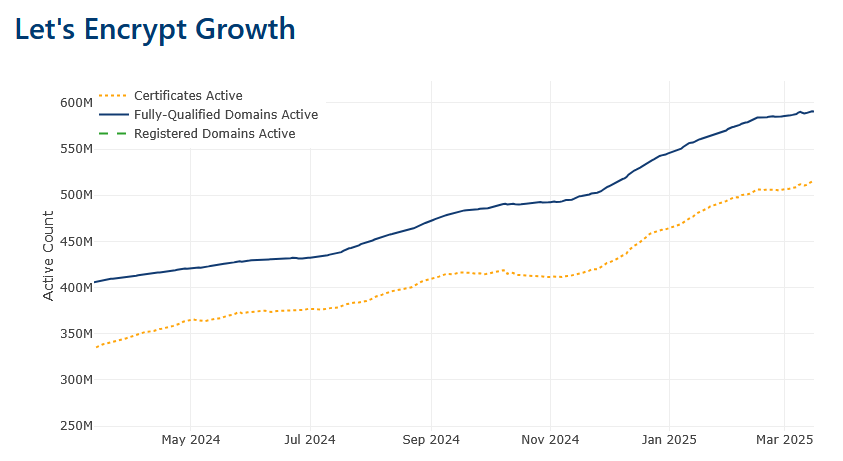
As of Feb 2025 LetsEncrypt has over 500 million verified domains with certificates issued. I have chosen LetsEncrypt for this research because the other leading provider of TLS certificates, Cloudflare, also has additional technologies in place to detect and ban malicious sites on their infrastructure.
LetsEncrypt's Certificate Transparency logs also provide logging for many other providers so we are not limited to only their certificates.
LetsEncrypt provides a rotating list of logs, usually with 180 day validity windows, these are available here. https://letsencrypt.org/docs/ct-logs/
For the purposes of this research we will use Oak 2025h1
Name: Oak 2025h1
URI: https://oak.ct.letsencrypt.org/2025h1
Public Key: MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEKeBpU9ejnCaIZeX39EsdF5vDvf8ELTHdLPxikl4y4EiROIQfS4ercpnMHfh8+TxYVFs3ELGr2IP7hPGVPy4vHA==
Log ID: A2:E3:0A:E4:45:EF:BD:AD:9B:7E:38:ED:47:67:77:53:D7:82:5B:84:94:D7:2B:5E:1B:2C:C4:B9:50:A4:47:E7
Window Start: 2024-12-20T00:00Z
Window End: 2025-07-20T00:00Z
State: Usable
If you are reading this in the future, this will likely be out of date and you will need to find the current usuable logs with an appropriate validity window.
There are several commercial & open-source tools and API's available that allow you to scrape these API's or directly query URLs. For this project I created my own implementation in Golang to output this data into a postgres database.
The full technical specification for the CT api is available here https://www.rfc-editor.org/rfc/rfc6962, if you are interested in implementing something for yourself.
Fair warning, there are a lot of certificates in these logs. It would take me about 4 weeks to fetch & ingest all of the certificates from just this one CT log.
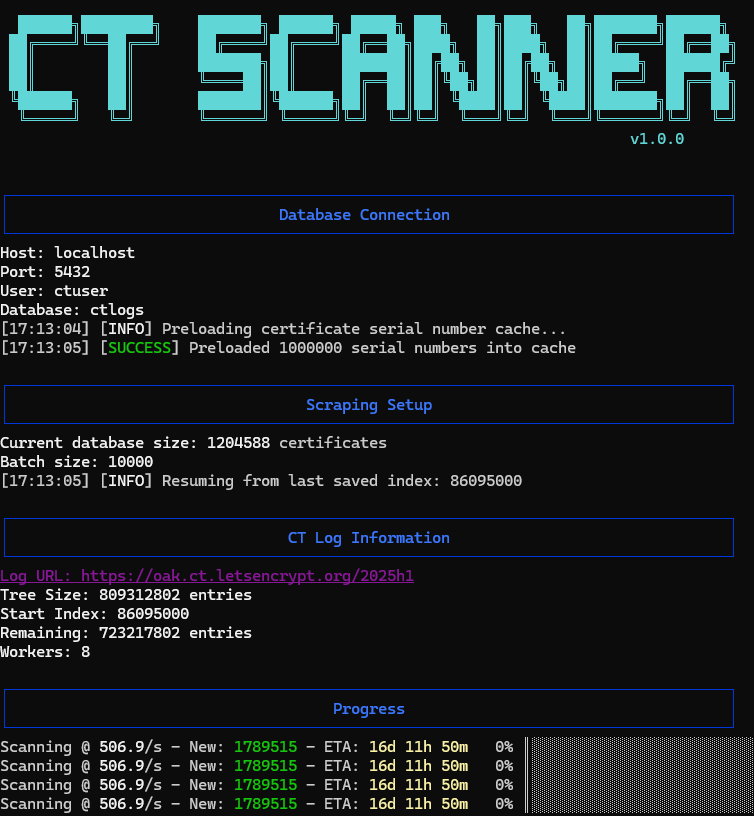
Luckily, after a couple of hours we have enough data to start investigating.
Investigating the data
At this point, if you don't have the CT data in a database you may run into some issues, as we'll initially be querying millions of rows.
I'm writing this before the full scrape is finished, so I currently have approximately 4 million certificates.
Let's start searching.
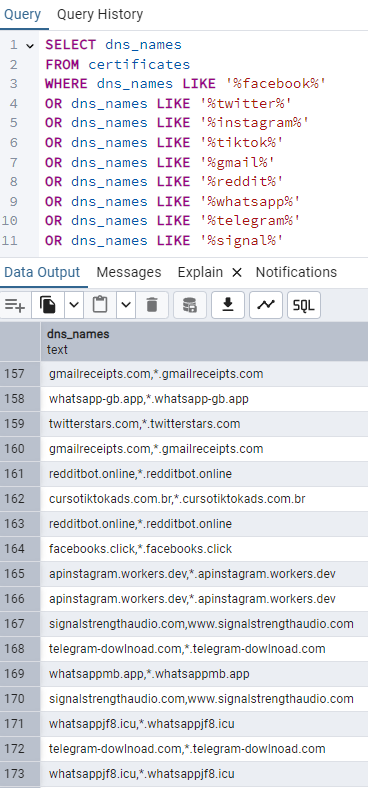
This fairly rudimentary query just searches for the domain names, with no tld of some of the most popular social websites.
This query returned 4600 results, and already we can see what are almost certainly some malicious results that warrant a deeper look.
It's important to note that this query returned many perfectly legitmate domains, so refining your query is extremely important and you may have your own patterns that you wish to search for.
Now we have some suspicious domains, but we have a problem. Phishing and malware infrastructure gets burnt all the time. Domains are cheap and TLS is free so threat actors are constantly changing and rotating, once a domain is flagged it's not worth their time to try to fix this and they will simply move to a new domain.
So we need to check whether the websites has some valid DNS, and is actually live.
This is a basic python script that will scan a list of domains in the format as shown in the screenshot.
pip install dnspython colorama tqdmimport dns.resolver
import csv
from colorama import init, Fore
import concurrent.futures
from tqdm import tqdm
# Initialize colorama
init()
def check_dns(domain):
try:
# Remove any wildcards and get the base domain
domain = domain.split(',')[0].strip('"')
# Perform DNS lookup
answers = dns.resolver.resolve(domain, 'A')
return (domain, True)
except:
return (domain, False)
def main():
# Read domains from CSV
domains = []
print(f"{Fore.WHITE}Reading domains from CSV...")
with open('domains.csv', 'r') as file:
for line in file:
domain = line.split(',')[0].strip('"')
if domain: # Skip empty lines
domains.append(domain)
# Remove duplicates
domains = list(set(domains))
total_domains = len(domains)
print(f"{Fore.WHITE}Found {total_domains} unique domains to check\n")
valid_domains = []
invalid_domains = []
# Use ThreadPoolExecutor for parallel processing
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
future_to_domain = {executor.submit(check_dns, domain): domain for domain in domains}
# Create progress bar
with tqdm(total=total_domains, desc="Checking DNS", unit="domain") as pbar:
for future in concurrent.futures.as_completed(future_to_domain):
domain, is_valid = future.result()
if is_valid:
valid_domains.append(domain)
print(f"{Fore.GREEN}[+] Valid DNS: {domain}")
else:
invalid_domains.append(domain)
print(f"{Fore.RED}[-] Invalid DNS: {domain}")
pbar.update(1)
# Print summary
print(f"\n{Fore.WHITE}=== Summary ===")
print(f"{Fore.GREEN}Valid domains: {len(valid_domains)}")
print(f"{Fore.RED}Invalid domains: {len(invalid_domains)}")
# Write results to CSV
print(f"\n{Fore.WHITE}Writing results to dns_results.csv...")
with open('dns_results.csv', 'w', newline='') as file:
writer = csv.writer(file)
#writer.writerow(['Domain', 'Status'])
for domain in valid_domains:
writer.writerow([domain])
#writer.writerow([domain, 'Valid'])
#for domain in invalid_domains:
#writer.writerow([domain, 'Invalid'])
print(f"{Fore.WHITE}Done! Results saved to dns_results.csv")
if __name__ == "__main__":
main()At this point, we have a csv file full of domains that at the very least have valid DNS configuration, and match our wildcard search for similarity to some popular social media sites.
Next let's see if these are actually online.
Many advanced actors will rotate active servers & domains, only allow certain IP's to connect or have other rules and conditions to actually access a website.
So an offline site in this case might mean that the domain is not accessible to your IP, at this time, with your current user-agent. So some creativity is needed here, but it's a good basic check.
If you've followed on from the script above the following script will check the domains and output valid ones, which in this case is HTTP status 200
import requests
import csv
from colorama import init, Fore
from tqdm import tqdm
import concurrent.futures
import time
from urllib3.exceptions import InsecureRequestWarning
# Suppress only the single warning from urllib3 needed.
requests.packages.urllib3.disable_warnings(category=InsecureRequestWarning)
# Initialize colorama
init()
# Headers to mimic a browser
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def check_url(url):
# Add http:// if no protocol specified
if not url.startswith(('http://', 'https://')):
url = f'http://{url}'
try:
# Try HTTPS first
response = requests.get(f'https://{url.replace("http://", "").replace("https://", "")}',
headers=HEADERS,
timeout=5,
verify=False)
return (url, response.status_code, 'https')
except:
try:
# Fall back to HTTP
response = requests.get(url,
headers=HEADERS,
timeout=5,
verify=False)
return (url, response.status_code, 'http')
except requests.exceptions.RequestException as e:
return (url, 'Error', str(e)[:50]) # Truncate error message
def main():
# Read URLs from file
urls = []
print(f"{Fore.WHITE}Reading URLs from file...")
with open('valid_domains.txt', 'r') as file:
urls = [line.strip() for line in file if line.strip()]
total_urls = len(urls)
print(f"{Fore.WHITE}Found {total_urls} URLs to check\n")
results = []
# Use ThreadPoolExecutor for parallel processing
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
future_to_url = {executor.submit(check_url, url): url for url in urls}
# Create progress bar
with tqdm(total=total_urls, desc="Checking URLs", unit="url") as pbar:
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
url, status, protocol = future.result()
results.append([url, status, protocol])
# Color code the output
if isinstance(status, int) and 200 <= status < 400:
print(f"{Fore.GREEN}[+] {url} - {status} ({protocol})")
else:
print(f"{Fore.RED}[-] {url} - {status} ({protocol})")
except Exception as e:
results.append([url, 'Error', str(e)[:50]])
print(f"{Fore.RED}[-] {url} - Error: {str(e)[:50]}")
pbar.update(1)
# Write results to CSV
print(f"\n{Fore.WHITE}Writing results to url_status.csv...")
with open('url_status.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['URL', 'Status', 'Protocol/Error'])
writer.writerows(results)
# Print summary
success = sum(1 for r in results if isinstance(r[1], int) and 200 <= r[1] < 400)
print(f"\n{Fore.WHITE}=== Summary ===")
print(f"{Fore.GREEN}Successful connections: {success}")
print(f"{Fore.RED}Failed connections: {total_urls - success}")
print(f"{Fore.WHITE}Results saved to url_status.csv")
if __name__ == "__main__":
main()So here are our results:
4+ million certificates
4678 matched our wildcard search
3268 had some kind of valid A type DNS record
1255 were online, with some kind of web server responding
In future posts we will look at how to gather more information using our refined domain lists, including what techniques and software we can use for analysis.
In the mean time, the CT api scraper will keep running, and thank you for reading.